[TFLite] 8. 텐서플로 라이트 모델의 성능 개선
텐서플로 라이트 모델의 성능 개선
이 포스팅에서는 안드로이드 기기의 다양한 하드웨어 가속을 활용하여 추론 성능을 개선하는 방법을 알아봅니다. 기기에서 추론할 때 CPU의 멀티 스레드를 활용하거나 GPU와 NNAPI에 위임하는 방법을 통해 추론 성능을 높일 수 있습니다.
추론 성능 측정
먼저 모델의 현재 추론 성능을 측정해봅니다.
안드로이드 기기에서 모델의 성능을 측정하는 방법은 텐서플로 웹 사이트의 다음 페이지에서 확인할 수 있습니다. Adb를 활용한 CLI 환경에서의 성능 벤치마크 방법, 안드로이드 스튜디오의 CPU 프로파일러를 활용한 성능 측정 방법 등이 소개되어 있습니다.
https://www.tensorflow.org/lite/performance/measurement
그러나 여기서는 간단한 코드를 추가하여 모델의 성능 시간을 측정해보도록 하겠습니다. 여기서 사용하는 코드는 TFLite 6장 포스팅에서 작성한 프로젝트의 코드들입니다.
먼저 activity_photo.xml에 추론 시간을 나타낼 텍스트 뷰를 추가합니다.

그리고 PhotoActivity.kt 파일에서 모델의 classify 메서드를 호출하는 callClassify 메서드에 모델의 추론 속도를 측정하는 코드를 추가합니다.
private fun callClassifier(bitmap: Bitmap?): String{
val startTime = SystemClock.uptimeMillis() // 모델 성능 측정
val output: Pair<String, Float> = classifier.classify(bitmap)
val elapsedTime = SystemClock.uptimeMillis() - startTime // 모델 성능 측정
val resultStr = String.format(Locale.ENGLISH,
"class : %s Prob : %.2f%%",
output.first, output.second * 100)
binding.textLog.text = "$elapsedTime ms" // 모델 성능 측정
return resultStr
}
추론 성능 개선
동일한 딥러닝 모델을 사용하더라도 기기에서 추론할 때 몇 가지 옵션을 이용하면 성능을 더욱 개선할 수 있습니다. CPU의 여러 스레드를 동시에 이용하거나 GPU를 이용하여 모델을 수행할 수도 있고, 안드로이드 8.1(SDK 27) 버전부터 제공하는 NNAPI를 사용하도록 위임하는 방법도 있습니다.
CPU 멀티 스레드
CPU 멀티스레드는 실시간 이미지 처리 등의 작업을 처리할 때 유용합니다.
멀티스레드를 이용하기 위해서는 Model이나 Interpreter 생성 시 추가적인 옵션을 제공하여 추론할 때 여러 스레드를 동시에 활용하도록 구현할 수 있습니다.
// 추론 성능 개선: CPU 멀티 스레드
private fun createMultiThreadModel(nThreads: Int): Model{
try {
val optionsBuilder = Model.Options.Builder()
optionsBuilder.setNumThreads(nThreads)
return Model.createModel(context, MODEL_NAME, optionsBuilder.build())
}catch(ioe: IOException){
throw ioe
}
}
Model.createModel( ) 함수를 호출하기 전에 Model.Options를 설정하기 위해 옵션의 빌더를 먼저 생성합니다.
그리고 Model.Options.Builder에 setNumThreads( ) 함수로 사용하고자 하는 스레드의 개수를 전달합니다.
createModel( ) 함수를 호출할 때 빌더의 build( ) 함수를 호출하여 Model.Options 인스턴스를 생성해서 전달하면 옵션이 적용된 모델이 생성됩니다.
Interpreter의 경우에도 마찬가지입니다.
private fun createMultiThreadInterpreter(nThreads: Int): Interpreter{
try{
val options = Interpreter.Options()
options.setNumThreads(nThreads)
val model = FileUtil.loadMappedFile(context, MODEL_NAME)
model.order(ByteOrder.nativeOrder())
return Interpreter(model, options)
}catch(ioe: IOException){
throw ioe
}
}
스레드가 일정 개수를 넘어가면 오히려 성능이 나빠지기 때문에 적절한 스레드 개수를 설정하는 것이 중요합니다.
GPU 위임
GPU를 사용할 경우 Model이나 Interpreter 생성 시 GPU를 활용하는 옵션을 추가하면 모델이 추론할 때 기기의 GPU에서 계산을 수행합니다.
GPU 위임을 사용하기 위해서는 먼저 build.gradle에 의존성을 추가해야 합니다.
dependencies {
...
// 추론 성능 개선: GPU 위임
implementation 'org.tensorflow:tensorflow-lite-gpu:2.4.0'
...
}
다음으로 GPU를 이용하는 모델을 반환하는 함수를 정의합니다.
// 추론 성능 개선: GPU 위임
private fun createGPUModel(): Model {
try {
val optionsBuilder = Model.Options.Builder()
val compatList = CompatibilityList()
if (compatList.isDelegateSupportedOnThisDevice)
optionsBuilder.setDevice(Model.Device.GPU)
return Model.createModel(context, MODEL_NAME, optionsBuilder.build())
}catch(ioe: IOException){
throw ioe
}
}
Model 대신 Interpreter를 사용하려면 다음과 같이 구현합니다.
private fun createGPUInterpreter(): Interpreter{
try{
val options = Interpreter.Options()
val compatList = CompatibilityList()
if(compatList.isDelegateSupportedOnThisDevice){
val delegateOptions = compatList.bestOptionsForThisDevice
val gpuDelegate = GpuDelegate(delegateOptions)
options.addDelegate(gpuDelegate)
}
val model = FileUtil.loadMappedFile(context, MODEL_NAME)
model.order(ByteOrder.nativeOrder())
return Interpreter(model, options)
}catch(ioe: IOException){
throw ioe
}
}
NNAPI 위임
NNAPI는 On-Device AI를 지원하기 위한 C언어 기반의 Native API로, 기기 내에서 인공 신경망 모델을 학습시키거나 추론하는 데 필요한 다양한 기능을 제공합니다.
텐서플로 라이트와 같은 고수준 프레임워크는 NNAPI를 이용하면 안드로이드 기기가 제공하는 다양한 하드웨어 가속을 지원받아 추론을 수행할 수 있습니다.
NNAPI는 기기의 환경에 따라 GPU나 DSP, NPU 등 가용한 여러 프로세서에서 필요한 연산을 효율적으로 분산할 수 있습니다.
| 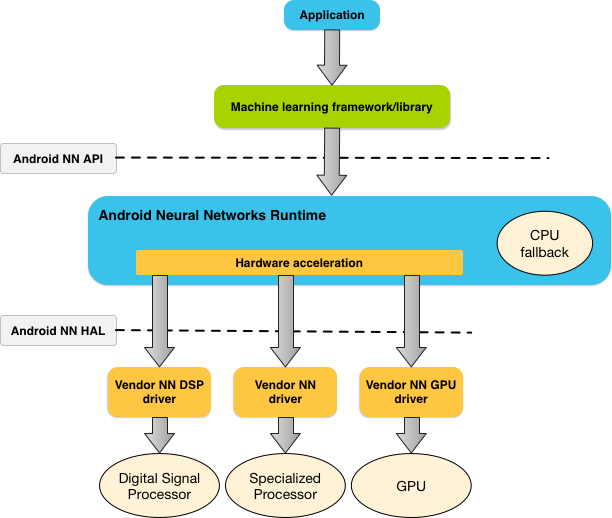 |
NNAPI는 HAL 계층과 머신러닝 프레임워크 사이에 위치하면서 전용 하드웨어를 적절히 이용할 수 있도록 제공하는 역할을 합니다. 만약 가용한 전용 프로세서나 드라이버가 없다면 CPU를 이용하여 연산을 수행합니다.
기기에서 추론에 NNAPI를 이용하려면 다음 코드와 같이 옵션을 설정하여 모델을 생성합니다.
// 추론 성능 개선: NNAPI 위임
private fun createNNAPIModel(): Model{
try{
val optionsBuilder = Model.Options.Builder()
if(Build.VERSION.SDK_INT >= Build.VERSION_CODES.P)
optionsBuilder.setDevice(Model.Device.NNAPI)
return Model.createModel(context, MODEL_NAME, optionsBuilder.build())
}catch(ioe: IOException){
throw ioe
}
}
Interpreter를 사용하는 코드는 다음과 같습니다.
private fun createNNAPIInterpreter(): Interpreter{
try{
val options = Interpreter.Options()
if(Build.VERSION.SDK_INT >= Build.VERSION_CODES.P){
val nnApiDelegate = NnApiDelegate()
options.addDelegate(nnApiDelegate)
}
val model = FileUtil.loadMappedFile(context, MODEL_NAME)
model.order(ByteOrder.nativeOrder())
return Interpreter(model, options)
}catch(ioe: IOException){
throw ioe
}
}
Leave a comment