[Programmers] [1차] 추석 트래픽
문제 설명
문제 설명
이번 추석에도 시스템 장애가 없는 명절을 보내고 싶은 어피치는 서버를 증설해야 할지 고민이다. 장애 대비용 서버 증설 여부를 결정하기 위해 작년 추석 기간인 9월 15일 로그 데이터를 분석한 후 초당 최대 처리량을 계산해보기로 했다. 초당 최대 처리량은 요청의 응답 완료 여부에 관계없이 임의 시간부터 1초(=1,000밀리초)간 처리하는 요청의 최대 개수를 의미한다.
입력 형식
solution함수에 전달되는lines배열은 N(1 ≦ N ≦ 2,000)개의 로그 문자열로 되어 있으며, 각 로그 문자열마다 요청에 대한 응답완료시간 S와 처리시간 T가 공백으로 구분되어 있다.- 응답완료시간 S는 작년 추석인 2016년 9월 15일만 포함하여 고정 길이
2016-09-15 hh:mm:ss.sss형식으로 되어 있다. - 처리시간 T는
0.1s,0.312s,2s와 같이 최대 소수점 셋째 자리까지 기록하며 뒤에는 초 단위를 의미하는s로 끝난다. - 예를 들어, 로그 문자열
2016-09-15 03:10:33.020 0.011s은 “2016년 9월 15일 오전 3시 10분 33.010초“부터 “2016년 9월 15일 오전 3시 10분 33.020초“까지 “0.011초” 동안 처리된 요청을 의미한다. (처리시간은 시작시간과 끝시간을 포함) - 서버에는 타임아웃이 3초로 적용되어 있기 때문에 처리시간은 0.001 ≦ T ≦ 3.000이다.
lines배열은 응답완료시간 S를 기준으로 오름차순 정렬되어 있다.
출력 형식
solution함수에서는 로그 데이터lines배열에 대해 초당 최대 처리량을 리턴한다.
입출력 예제
예제1
- 입력: [ “2016-09-15 01:00:04.001 2.0s”, “2016-09-15 01:00:07.000 2s” ]
- 출력: 1
예제2
- 입력: [ “2016-09-15 01:00:04.002 2.0s”, “2016-09-15 01:00:07.000 2s” ]
- 출력: 2
- 설명: 처리시간은 시작시간과 끝시간을 포함하므로
첫 번째 로그는
01:00:02.003 ~ 01:00:04.002에서 2초 동안 처리되었으며, 두 번째 로그는01:00:05.001 ~ 01:00:07.000에서 2초 동안 처리된다. 따라서, 첫 번째 로그가 끝나는 시점과 두 번째 로그가 시작하는 시점의 구간인01:00:04.002 ~ 01:00:05.0011초 동안 최대 2개가 된다.
예제3
- 입력: [ “2016-09-15 20:59:57.421 0.351s”, “2016-09-15 20:59:58.233 1.181s”, “2016-09-15 20:59:58.299 0.8s”, “2016-09-15 20:59:58.688 1.041s”, “2016-09-15 20:59:59.591 1.412s”, “2016-09-15 21:00:00.464 1.466s”, “2016-09-15 21:00:00.741 1.581s”, “2016-09-15 21:00:00.748 2.31s”, “2016-09-15 21:00:00.966 0.381s”, “2016-09-15 21:00:02.066 2.62s” ]
- 출력: 7
- 설명: 아래 타임라인 그림에서 빨간색으로 표시된 1초 각 구간의 처리량을 구해보면
(1)은 4개,(2)는 7개,(3)는 2개임을 알 수 있다. 따라서 초당 최대 처리량은 7이 되며, 동일한 최대 처리량을 갖는 1초 구간은 여러 개 존재할 수 있으므로 이 문제에서는 구간이 아닌 개수만 출력한다.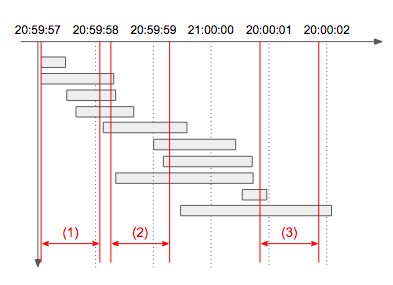
문제 풀이
# 완전 탐색
알고리즘에 대해 설명하기 전에, 참고로 저는 처음에는
큐로 풀이하려 했습니다.for log in lines에서 입력들을 보며 바로 답을 구할 수 있게끔요.그래서 ‘리스트 맨 앞에 있는 요청의 종료 시각 + 1(s) <= 현재 입력되는 요청의 시작 시각’이면
processing.append(len(reqs) - 1)하고reqs.pop(0)하는 식으로 풀이하려 했으나… (processing은 각 요청의 종료 시각부터 1초 구간 내의 최대 요청 수, reqs는 for문에서 현재까지 입력된 요청 수)이 알고리즘은 다음 요청은 1초 구간 안에 없어도, 다음 요청 이후의 요청들은 1초 구간 안에 속할 수 있다는 것을 캐치하지 못하기 때문에 옳지 않은 풀이더라구요… (입력은 종료 시각으로 정렬되어 있지 시작 시각으로 정렬되어 있지는 않기 때문에 이후의 모든 요청들을 검사해야 합니다)
그냥 아이디어가 아까워서 끄적여 봅니다 ㅎㅎ
그럼 각설하고 풀이를 보시죠!
👍 Step 1. 시간 계산하기
입력 파라미터로 종료 시각과 처리 시간이 들어옵니다.
우리는 1초 동안에 최대 요청의 수를 계산해야 하기 때문에, 저 두 개의 파라미터로 시작 시각을 계산해야 합니다.
종료 시각 부분에서 날짜는 필요없습니다. (9월 15일만 고려하기 때문)
따라서 날짜를 제외한 종료 시각과 처리 시간을 넘겨주어 시작 시각을 계산해주는 get_start_time 함수를 하나 정의합니다. 이 과정에서 시각을 넘겨주면 이것을 초로 환산하여 반환해주는 get_time 함수도 정의합니다.
이 때, 우리는 시각 간의 대소 관계만이 중요하기 때문에, 시각의 포맷은 신경 쓰지 않습니다.
따라서 다음과 같이 계산할 수 있습니다.
def get_time(time):
h, m, s = time.split(':')
return int(h)*3600 + int(m)*60 + float(s)
def get_start_time(endtime, spantime):
return get_time(endtime) - float(spantime) + 0.001
시, 분, 초 를 모두 초 단위로 환산하여 계산한 것입니다.
👍 Step 2. 이후 요청들에 대해 완전 탐색하기
그리고 두 번째, 이 계산된 [시작시각, 종료시각] 들을 담은 리스트에서 각 요청의 종료 시각을 기준으로 1초 동안 몇 개의 요청이 존재하는 지 검사합니다.
각 요청의 종료 시각을 기준으로 현재 요청의 종료 시각 + 1(s) > 이후 요청의 시작 시각 이면 1초 구간 내에 들어있는 요청입니다.
이것이 가능한 이유는 입력으로 들어온 lines 파라미터가 종료 시각을 기준으로 오름차순 정렬되어 있기 때문입니다.
def solution(lines):
processing = []
reqs = []
for log in lines:
date, endtime, spantime = log.split()
starttime = get_start_time(endtime, spantime[:-1])
endtime = get_time(endtime)
reqs.append([starttime, endtime])
for i in range(len(reqs)):
cnt = 0
for j in range(i,len(reqs)):
if reqs[i][1]+1 > reqs[j][0]:
cnt += 1
processing.append(cnt)
return max(processing)
👍 전체 코드
전체 코드는 아래와 같습니다!
def get_time(time):
h, m, s = time.split(':')
return int(h)*3600 + int(m)*60 + float(s)
def get_start_time(endtime, spantime):
return get_time(endtime) - float(spantime) + 0.001
def solution(lines):
processing = []
reqs = []
for log in lines:
date, endtime, spantime = log.split()
starttime = get_start_time(endtime, spantime[:-1])
endtime = get_time(endtime)
reqs.append([starttime, endtime])
for i in range(len(reqs)):
cnt = 0
for j in range(i,len(reqs)):
if reqs[i][1]+1 > reqs[j][0]:
cnt += 1
processing.append(cnt)
return max(processing)
👍 참고
다른 분들 풀이를 보면 시각을 밀리초로 환산하여 계산한 분들도 계시던데…
저는 파이썬 언어를 사용해서 초로만 환산해도 통과했지만, 다른 언어를 사용할 시에 float 변환 과정에서 문제가 생길 수도 있는 것 같아요. (확실치는 않지만..)
그래서 밀리초로 환산해서 float를 사용하지 않고 int만 사용하는 풀이들이 있습니다.
파이썬으로 작성된 밀리초로 환산하는 풀이도 밑에 참고로 올려놓겠습니다.
def get_time(time):
h, m, s, ms = map(int,[time[:2], time[3:5], time[6:8], time[9:]])
return (h*3600 + m*60 + s)*1000 + ms
def get_start_time(endtime, spantime):
s, ma = map(int,spantime.split('.'))
return get_time(endtime) - (s*1000 + ms) + 1
def solution(lines):
processing = []
reqs = []
for log in lines:
date, endtime, spantime = log.split()
starttime = get_start_time(endtime, spantime[:-1])
endtime = get_time(endtime)
reqs.append([starttime, endtime])
for i in range(len(reqs)):
cnt = 0
for j in range(i,len(reqs)):
if reqs[i][1]+1000 > reqs[j][0]:
cnt += 1
processing.append(cnt)
return max(processing)
+ 추가
참고로, 혹시 3번과 18번 테스트케이스만 틀린다면 제가 앞에서 얘기한 ’다음 요청은 1초 구간 안에 없어도, 다음 요청 이후의 요청들은 1초 구간 안에 속할 수 있다’는 것을 캐치하지 못해서 일겁니다!
Leave a comment