[Machine Learning] Hyperparameter Tuning
Hyperparameter Tuning
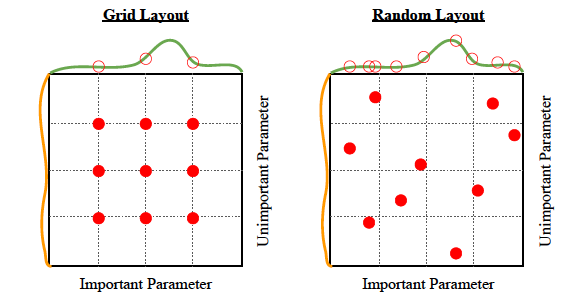
- to choose a set of optimal hyperparameters for a learning algorithm
- example case: Bike Renting Analysis problem (from kaggle)
Setup
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn import svm
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.metrics import make_scorer
%matplotlib inline
Import dataset
!curl -L https://goo.gl/s8qSL5 -o ./bike_train.csv
# !curl https://goo.gl/s8qSL5 -o ../Lab_M2/data/bike_train.csv
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 139 0 139 0 0 166 0 --:--:-- --:--:-- --:--:-- 2355
100 318 100 318 0 0 263 0 0:00:01 0:00:01 --:--:-- 263
0 0 0 0 0 0 0 0 --:--:-- 0:00:02 --:--:-- 0
58 643k 58 375k 0 0 140k 0 0:00:04 0:00:02 0:00:02 625k
100 643k 100 643k 0 0 231k 0 0:00:02 0:00:02 --:--:-- 911k
train = pd.read_csv("bike_train.csv")
train.dtypes
datetime object
season int64
holiday int64
workingday int64
weather int64
temp float64
atemp float64
humidity int64
windspeed float64
casual int64
registered int64
count int64
dtype: object
Data read and Preprocessing
train = pd.read_csv("bike_train.csv", parse_dates=["datetime"])
train.dtypes
datetime datetime64[ns]
season int64
holiday int64
workingday int64
weather int64
temp float64
atemp float64
humidity int64
windspeed float64
casual int64
registered int64
count int64
dtype: object
train.head(3)
| datetime | season | holiday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 3 | 13 | 16 |
| 1 | 2011-01-01 01:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 8 | 32 | 40 |
| 2 | 2011-01-01 02:00:00 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 5 | 27 | 32 |
train.shape # (10886, 12)
(10886, 12)
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10886 entries, 0 to 10885
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 datetime 10886 non-null datetime64[ns]
1 season 10886 non-null int64
2 holiday 10886 non-null int64
3 workingday 10886 non-null int64
4 weather 10886 non-null int64
5 temp 10886 non-null float64
6 atemp 10886 non-null float64
7 humidity 10886 non-null int64
8 windspeed 10886 non-null float64
9 casual 10886 non-null int64
10 registered 10886 non-null int64
11 count 10886 non-null int64
dtypes: datetime64[ns](1), float64(3), int64(8)
memory usage: 1020.7 KB
- decompose ‘datetime’ feature
train["d-year"] = train["datetime"].dt.year
train["d-month"] = train["datetime"].dt.month
train["d-day"] = train["datetime"].dt.day
train["d-hour"] = train["datetime"].dt.hour
train["d-minute"] = train["datetime"].dt.minute
train["d-second"] = train["datetime"].dt.second
train["d-dayofweek"] = train["datetime"].dt.dayofweek # monday(0), ... sunday(6)
train[["datetime", "d-year", "d-month", "d-day", "d-hour",
"d-minute", "d-second", "d-dayofweek"]].head()
| datetime | d-year | d-month | d-day | d-hour | d-minute | d-second | d-dayofweek | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2011-01-01 00:00:00 | 2011 | 1 | 1 | 0 | 0 | 0 | 5 |
| 1 | 2011-01-01 01:00:00 | 2011 | 1 | 1 | 1 | 0 | 0 | 5 |
| 2 | 2011-01-01 02:00:00 | 2011 | 1 | 1 | 2 | 0 | 0 | 5 |
| 3 | 2011-01-01 03:00:00 | 2011 | 1 | 1 | 3 | 0 | 0 | 5 |
| 4 | 2011-01-01 04:00:00 | 2011 | 1 | 1 | 4 | 0 | 0 | 5 |
figure, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2)
figure.set_size_inches(12, 6)
sns.barplot(data=train, x="d-year", y="count", ax=ax1)
sns.barplot(data=train, x="d-month", y="count", ax=ax2)
sns.barplot(data=train, x="d-day", y="count", ax=ax3)
sns.barplot(data=train, x="d-hour", y="count", ax=ax4)

Data Analysis
average numbers of rentals by hour (weekdays and weekends)
- pointplot():point estimates and confidence intervals using scatter plot
- It is important to keep in mind that a point plot shows only the mean (or other estimator) value, but in many cases it may be more informative to show the distribution of values at each level of the categorical variables. In that case, other approaches such as a box or violin plot may be more appropriate.
plt.figure(figsize=(12,4))
# sns.pointplot(data=train, x="d-hour", y="count", hue="workingday")
sns.pointplot(data=train, x="d-hour", y="count")

plt.figure(figsize=(12,4))
sns.pointplot(data=train, x="d-hour", y="count", hue="workingday")

average number of rentals (weekdays)
- dayofweek: return the day of the week. It is assumed the week starts on Monday, which is denoted by 0 and ends on Sunday which is denoted by 6. This method is available on both Series with datetime values (using the dt accessor) or DatetimeIndex.
print(train.shape)
train[["datetime", "d-dayofweek"]].head()
(10886, 19)
| datetime | d-dayofweek | |
|---|---|---|
| 0 | 2011-01-01 00:00:00 | 5 |
| 1 | 2011-01-01 01:00:00 | 5 |
| 2 | 2011-01-01 02:00:00 | 5 |
| 3 | 2011-01-01 03:00:00 | 5 |
| 4 | 2011-01-01 04:00:00 | 5 |
figure, (ax1, ax2) = plt.subplots(nrows=2, ncols=1)
figure.set_size_inches(18, 8)
sns.pointplot(data=train, x="d-hour", y="count", hue="workingday", ax=ax1)
sns.pointplot(data=train, x="d-hour", y="count", hue="d-dayofweek", ax=ax2)

generating a new feature by combining year and month
def concatenate_year_month(datetime):
return "{0}-{1}".format(datetime.year, datetime.month)
train["d-year_month"] = train["datetime"].apply(concatenate_year_month)
print(train.shape)
train[["datetime", "d-year_month"]].head()
(10886, 20)
| datetime | d-year_month | |
|---|---|---|
| 0 | 2011-01-01 00:00:00 | 2011-1 |
| 1 | 2011-01-01 01:00:00 | 2011-1 |
| 2 | 2011-01-01 02:00:00 | 2011-1 |
| 3 | 2011-01-01 03:00:00 | 2011-1 |
| 4 | 2011-01-01 04:00:00 | 2011-1 |
figure, (ax1, ax2) = plt.subplots(nrows=1, ncols=2)
figure.set_size_inches(18, 4)
sns.barplot(data=train, x="d-year", y="count", ax=ax1)
sns.barplot(data=train, x="d-month", y="count", ax=ax2)
figure, ax3 = plt.subplots(nrows=1, ncols=1)
figure.set_size_inches(18, 4)
sns.barplot(data=train, x="d-year_month", y="count", ax=ax3)


Select features to use for training
train.columns
Index(['datetime', 'season', 'holiday', 'workingday', 'weather', 'temp',
'atemp', 'humidity', 'windspeed', 'casual', 'registered', 'count',
'd-year', 'd-month', 'd-day', 'd-hour', 'd-minute', 'd-second',
'd-dayofweek', 'd-year_month'],
dtype='object')
features = ["season", "holiday", "workingday", "weather",
"temp", "atemp", "humidity", "windspeed",
"d-year", "d-hour", "d-dayofweek"]
X = train[features]
y = train['count']
print(X.shape, y.shape)
X.head()
(10886, 11) (10886,)
| season | holiday | workingday | weather | temp | atemp | humidity | windspeed | d-year | d-hour | d-dayofweek | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 81 | 0.0 | 2011 | 0 | 5 |
| 1 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 2011 | 1 | 5 |
| 2 | 1 | 0 | 0 | 1 | 9.02 | 13.635 | 80 | 0.0 | 2011 | 2 | 5 |
| 3 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 2011 | 3 | 5 |
| 4 | 1 | 0 | 0 | 1 | 9.84 | 14.395 | 75 | 0.0 | 2011 | 4 | 5 |
Random Forest model
np.random.seed(11)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
model = RandomForestRegressor(n_estimators= 30)
model.fit(X_train, y_train)
model.score(X_test, y_test)
0.9483758264489849
use logarithmic distribution
from sklearn.metrics import mean_squared_error
np.random.seed(11)
X_train, X_test, y_train, y_test = train_test_split(X, np.log(1+y), test_size = 0.2) # y -> log(1 + y)
model = RandomForestRegressor(n_estimators= 30)
model.fit(X_train, y_train)
print("score: ", model.score(X_test, y_test))
print("MSE: ", mean_squared_error(y_test, model.predict(X_test)))
score: 0.9583998288123375
MSE: 0.08291535828416392
- we can see that log(1+y) gives better performance than y.
# list(zip(y_test, model.predict(X_test)))[:10]
# X_train[:5]
Other models: linear and decision tree models
y_train
7560 4.709530
8090 6.304449
30 0.693147
7290 1.945910
8665 5.521461
...
4023 5.913503
7259 5.817111
5200 5.153292
3775 5.192957
10137 6.144186
Name: count, Length: 8708, dtype: float64
model = LinearRegression()
model.fit(X_train, y_train)
print(model.score(X_test, y_test))
model = DecisionTreeRegressor()
model.fit(X_train, y_train)
print(model.score(X_test, y_test))
0.4725950198506106
0.9152295630854631
change the performance score (rmse -> rmsle)
- robust to outliers
- RMSLE incurs a larger penalty for the underestimation of the Actual variable than the Overestimation.
- This is especially useful for business cases where the underestimation of the target variable is not acceptable but overestimation can be tolerated.
- to be used in GridSearch() (The less, the better.)
- \[\sqrt{\frac{1}{n} \sum_{i=1}^n (\log(p_i + 1) - \log(a_i+1))^2 }\]
def rmsle(predict, actual):
predict = np.array(predict)
actual = np.array(actual)
predict = np.log(predict + 1)
actual = np.log(actual + 1)
difference_square_mean = np.square(predict - actual).mean()
score = np.sqrt(difference_square_mean)
return score
rmsle_scorer = make_scorer(rmsle) # make your own scoring function
rmsle_scorer
make_scorer(rmsle)
selecting hyperparameters
- Grid search
- Random search
Grid search
# Grid Search for the random forest
n_estimators = 30
max_depth_list = [10, 20, 30, 50, 100]
max_features_list = [0.1, 0.3, 0.5, 0.7, 0.9] # 사용할 특성의 비율
hyperparameters_list = []
for max_depth in max_depth_list:
for max_features in max_features_list:
model = RandomForestRegressor(n_estimators=n_estimators,
max_depth=max_depth,
max_features=max_features,
random_state=11,
n_jobs=-1)
score = cross_val_score(model, X_train, y_train, cv=5,
scoring=rmsle_scorer).mean()
hyperparameters_list.append({
'rmsle': score,
'n_estimators': n_estimators,
'max_depth': max_depth,
'max_features': max_features,
})
print("Score = {0:.5f}".format(score))
hyperparameters_list
Score = 0.16782
...
Score = 0.08654
[{'rmsle': 0.1678247426392651,
'n_estimators': 30,
'max_depth': 10,
'max_features': 0.1},
...
{'rmsle': 0.08653948703002194,
'n_estimators': 30,
'max_depth': 100,
'max_features': 0.9}]
hyperparameters_list = pd.DataFrame.from_dict(hyperparameters_list) # make dataframe from dictionary
hyperparameters_list = hyperparameters_list.sort_values(by="rmsle")
print(hyperparameters_list.shape)
hyperparameters_list.head()
(25, 4)
| rmsle | n_estimators | max_depth | max_features | |
|---|---|---|---|---|
| 19 | 0.086539 | 30 | 50 | 0.9 |
| 24 | 0.086539 | 30 | 100 | 0.9 |
| 14 | 0.086558 | 30 | 30 | 0.9 |
| 9 | 0.086676 | 30 | 20 | 0.9 |
| 8 | 0.087629 | 30 | 20 | 0.7 |
Random search
- 2 stages: random selection and fine tuning
# Random selection
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
hyperparameters_list = []
n_estimators = 30
num_epoch = 10
for epoch in range(num_epoch):
max_depth = np.random.randint(low=2, high=100)
max_features = np.random.uniform(low=0.1, high=1.0)
model = RandomForestRegressor(n_estimators=n_estimators,
max_depth=max_depth,
max_features=max_features,
random_state=37,
n_jobs=-1)
score = cross_val_score(model, X_train, y_train, cv=5,
scoring=rmsle_scorer).mean()
hyperparameters_list.append({
'rmsle': score,
'n_estimators': n_estimators,
'max_depth': max_depth,
'max_features': max_features,
})
print("Score = {0:.5f}".format(score))
hyperparameters_list = pd.DataFrame.from_dict(hyperparameters_list)
hyperparameters_list = hyperparameters_list.sort_values(by="rmsle")
print(hyperparameters_list.shape)
hyperparameters_list.head()
Score = 0.08673
Score = 0.12227
Score = 0.12227
Score = 0.14013
Score = 0.09152
Score = 0.18747
Score = 0.08869
Score = 0.08962
Score = 0.08869
Score = 0.08761
(10, 4)
| rmsle | n_estimators | max_depth | max_features | |
|---|---|---|---|---|
| 0 | 0.086729 | 30 | 76 | 0.804363 |
| 9 | 0.087607 | 30 | 82 | 0.708922 |
| 6 | 0.088695 | 30 | 79 | 0.575713 |
| 8 | 0.088695 | 30 | 74 | 0.577014 |
| 7 | 0.089616 | 30 | 12 | 0.700990 |
Fine tuning
# fine search
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
hyperparameters_list = []
n_estimators = 30
num_epoch = 10
for epoch in range(num_epoch):
max_depth = np.random.randint(low=30, high=90)
max_features = np.random.uniform(low=0.5, high=1.0)
model = RandomForestRegressor(n_estimators=n_estimators,
max_depth=max_depth,
max_features=max_features,
random_state=37,
n_jobs=-1)
score = cross_val_score(model, X_train, y_train, cv=5,
scoring=rmsle_scorer).mean()
hyperparameters_list.append({
'rmsle': score,
'n_estimators': n_estimators,
'max_depth': max_depth,
'max_features': max_features,
})
print("Score = {0:.5f}".format(score))
hyperparameters_list = pd.DataFrame.from_dict(hyperparameters_list)
hyperparameters_list = hyperparameters_list.sort_values(by="rmsle")
print(hyperparameters_list.shape)
hyperparameters_list
Score = 0.08640
Score = 0.08869
Score = 0.08658
Score = 0.08673
Score = 0.08761
Score = 0.08673
Score = 0.08640
Score = 0.08869
Score = 0.08658
Score = 0.08761
(10, 4)
| rmsle | n_estimators | max_depth | max_features | |
|---|---|---|---|---|
| 0 | 0.086401 | 30 | 59 | 0.847356 |
| 6 | 0.086401 | 30 | 39 | 0.830026 |
| 8 | 0.086583 | 30 | 83 | 0.930264 |
| 2 | 0.086583 | 30 | 54 | 0.949200 |
| 3 | 0.086729 | 30 | 48 | 0.765320 |
| 5 | 0.086729 | 30 | 64 | 0.728243 |
| 4 | 0.087607 | 30 | 85 | 0.661769 |
| 9 | 0.087607 | 30 | 65 | 0.688243 |
| 1 | 0.088695 | 30 | 89 | 0.598500 |
| 7 | 0.088695 | 30 | 65 | 0.578285 |
Final Selection
# final selection of hyperparameters (최종모델 선택)
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=300,
max_depth=65,
max_features=0.9309,
random_state=37,
n_jobs=-1)
model.fit(X_train, y_train)
score = cross_val_score(model, X_test, y_test, cv=5,
scoring=rmsle_scorer).mean()
print("Score = {0:.5f}".format(score))
Score = 0.09163
Most significant features
model.feature_importances_ # he higher, the more important the feature.
array([0.02895014, 0.00159298, 0.03771286, 0.01074947, 0.04924549,
0.02964683, 0.02133926, 0.01119758, 0.03024815, 0.75071977,
0.02859746])
df = pd.DataFrame({'feature':features,'importance':model.feature_importances_ })
df=df.sort_values('importance', ascending=False)
x = df.feature
y = df.importance
ypos = np.arange(len(x))
plt.figure(figsize=(10,7))
plt.barh(x, y)
plt.yticks(ypos, x)
plt.xlabel('Importance')
plt.ylabel('Variable')
plt.xlim(0, 1)
plt.ylim(-1, len(x))
plt.show()

GridSearchCV()
- 그리드 탐색을 하며 동시에 교차 검증 수행
- fit, model, score 함수를 제공하며 fit 를 호출할 때 여러 파라미터 조합에 대해 교차 검증을 수행
- Exhaustive search over specified parameter values for an estimator.
- it implements a “fit” and a “score” method. It also implements “predict”, “predict_proba”, “decision_function”, “transform” and “inverse_transform” if they are implemented in the estimator used.
- The parameters of the estimator used to apply these methods are optimized by cross-validated grid-search over a parameter grid.
- 그리드 탐색과 교차 검증을 동시에 수행
from sklearn.model_selection import GridSearchCV
params = [{"max_depth":[10, 20, 30],
"max_features":[0.3, 0.5, 0.9]}]
# grid search
clf = GridSearchCV(RandomForestRegressor(), params, cv=3, n_jobs=-1)
clf.fit(X_train, y_train)
print("best values: ", clf.best_estimator_)
print("best score: ", clf.best_score_)
# final evaluation on test data
score = clf.score(X_test, y_test)
print("final score: ", score)
best values: RandomForestRegressor(max_depth=30, max_features=0.9)
best score: 0.9464442332854327
final score: 0.9589943180667339
RandomizedSearchCV() function
- In contrast to GridSearchCV, not all parameter values are tried out, but rather a fixed number of parameter settings is sampled from the specified distributions. The number of parameter settings that are tried is given by n_iter.
from sklearn.model_selection import RandomizedSearchCV
n_estimators = [int(x) for x in np.linspace(start = 200, stop = 2000, num = 10)]
max_features = ['log2', 'sqrt']
max_depth = [int(x) for x in np.linspace(10, 110, num = 11)]
max_depth.append(None)
min_samples_split = [2, 5, 10]
min_samples_leaf = [1, 2, 4]
bootstrap = [True, False]
random_grid = {'n_estimators': n_estimators,
'max_features': max_features,
'max_depth': max_depth,
'min_samples_split': min_samples_split,
'min_samples_leaf': min_samples_leaf,
'bootstrap': bootstrap}
rf = RandomizedSearchCV(RandomForestRegressor(), random_grid,
cv = 3, n_jobs = -1)
# Fit the random search model
rf.fit(X_train, y_train)
print(rf.best_params_, rf.best_estimator_, rf.best_score_)
score = rf.score(X_test, y_test)
print(score)
{'n_estimators': 200, 'min_samples_split': 5, 'min_samples_leaf': 2, 'max_features': 'log2', 'max_depth': None, 'bootstrap': False} RandomForestRegressor(bootstrap=False, max_features='log2', min_samples_leaf=2,
min_samples_split=5, n_estimators=200) 0.9162766832621637
0.9365843295319143
Leave a comment