[Computer Vision] 7(4). VAE와 GAN으로 더 크고 현실적인 데이터셋 생성
VAE와 GAN으로 더 크고 현실적인 데이터셋 생성
VAE와 GAN은 최근 몇 년 간 머신러닝에서 가장 흥미로운 개발로 여겨지는 생성 모델이자 또 다른 도메인 적응 기법이다.
포스팅 내용에 대한 예시 코드들은 깃허브 저장소에서 확인할 수 있다.
판별 모델과 생성 모델
대부분의 모델은 판별(discrimination) 모델이다. 이는 입력이 주어졌을 때 그에 해당하는 정확한 출력을 반환/판별하기 위해 가중치를 학습하는 것을 말한다.
생성(Generation) 모델은 확률 분포 p(x)에서 뽑아낸 샘플 x가 주어졌을 때 ‘이 분포를 모델링’한다. 예를 들어 고양이를 나타내는 이미지 x가 주어졌을 때 생성 모델은 x와 동일한 집합에 속할 수 있는 새로운 고양이 이미지를 생성하기 위해 데이터 분포를 추론한다.
정리하면, 판별 모델은 특정 특징을 기반으로 사진을 인식하는 법을 학습하고, 생성 모델은 입력 도메인에서 전형적인 특징을 재생산해 새로운 이미지를 샘플링 하는 법을 학습한다.
VAE
변분 오토인코더(Variational auto-encoder, VAE)는 연속된 잠재 공간을 갖게끔 설계된 특수 오토인코더이며, 따라서 생성 모델로 사용된다. 이미지 x에 대응하는 코드를 직접 추출하는 대신 VAE의 인코더는 이미지가 속한 잠재 공간에서 ‘분포를 단순화한 추정값’을 제공해야 한다.
VAE가 새로운 이미지를 생성해내는 과정은 다음과 같다.
- 인코더가 두 개의 벡터를 반환한다. 하나는 다변량 정규분포의 평균으로 가장 이미지가 있을 법한 위치를 나타내고, 다른 하나는 표준 편차로 이미지가 있을 수 있는 해당 위치 주변의 원형 면적이다.
- 인코더에 의해 정의된 출력 분포로부터 랜덤 코드 z가 선택된다.
- 랜덤 코드 z가 디코더에 전달되고 디코더가 z를 기반으로 이미지를 재구성한다.

VAE의 손실로는 MSE와 함께 쿨백-라이블러 발산(KL 발산) 을 사용한다. KL 발산은 두 확률 분포 사이의 차이를 측정하여 인코더에 의해 정의된 분포가 표준 정규 분포 N(0, 1)에 충분히 가깝도록 손실에 맞춰 조정된다.
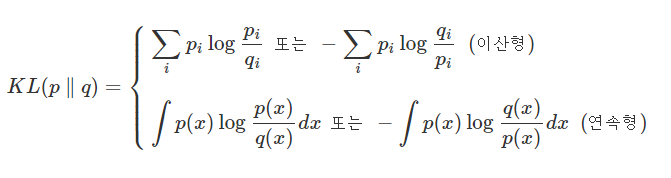
이 재매개변수화와 KL 손실을 사용해 오토인코더는 강력한 생성 모델이 된다.
모델이 훈련되면 인코더는 폐기될 수 있고, 디코더는 랜덤 벡터 z ~ N(0, 1)이 입력으로 주어지면 새로운 이미지를 생성하기 위해 바로 사용될 수 있다.
GAN
생성적 적대 신경망(Generative Adverserial Network, GAN)은 생성 작업에서 단연코 가장 유명한 솔루션이다.
이름에서 알 수 있듯이, GAN은 적대적 체계를 사용하므로 비지도 방식으로 훈련될 수 있다. GAN을 통해 생성된 이미지와 직접 비교할 실제 데이터가 존재하지 않기 때문에, 전형적인 손실 함수를 사용하지 않고 생성자 네트워크를 또 다른 네트워크인 판별자와 겨루게 한다.
판별자는 이미지가 원본 데이터셋에서 나온 것인지(‘실제’ 이미지) 아니면 다른 네트워크에 의해 생성됐는지(‘가짜’ 이미지)를 평가한다. 이 판별기에 대항해 생성기는 노이즈 벡터 z에 의해 조절된 새로운 이미지를 생성해 이 이미지가 ‘실제’ 이미지라고(즉, p(x)애소 샘플링됐다고) 믿도록 판별기를 속이려 한다.
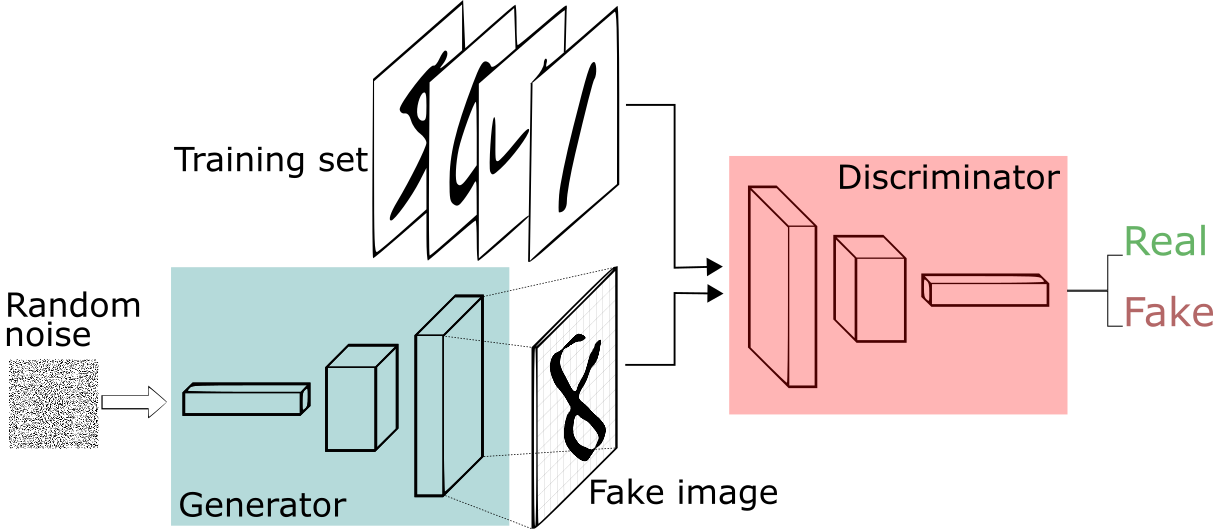
GAN은 ‘게임 이론’에서 영감을 받았으며 이 네트워크를 훈련하는 과정은 ‘2인용 제로섬 최소극대화 게임’으로 해석될 수 있다.
게임의 각 단계는 다음과 같이 수행된다.
- 생성기 G는 N개의 노이즈 벡터 z를 받아 그만큼의 이미지 xG를 출력한다.
- 이 N개의 가짜 이미지는 훈련 집합에서 선정된 N개의 실제 이미지 x와 혼합된다.
- 판별기 D는 이 혼합된 배치에서 훈련돼 어느 이미지가 ‘실제’이고 어느 이미지가 ‘가짜’인지 추정하려고 한다.
- 생성기 G는 또 다른 N개의 노이즈 벡터로 이루어진 배치에서 훈련돼 D가 그것들이 실제라고 여길 수 있도록 이미지를 생성하려고 한다.
따라서 이 과정을 반복할 때마다 판별기 D는 게임 보상 V(G, D)를 최대화하려고 하는 반면, 생성기 G는 이를 최소화하려고 한다.

게임 이론에 따라 ‘최소 극대화 게임’의 결과는 G와 D 사이의 균형(내시 균형, Nash Equlibrium)이다.
실제로 GAN을 사용해 달성하기 어렵지만, 훈련 과정은 D가 ‘실제’와 ‘가짜’를 구별할 수 없고(즉, 모든 샘플에 대해 D(x) = 1/2이고 D(G(x)) = 1/2) G가 타깃 분포 p(x)를 모델링하는 것으로 마무리된다.
GAN을 훈련시키기는 어렵지만 상당히 현실적인 결과를 만들어내므로 새로운 데이터 샘플을 생성하기 위해 일반적으로 사용된다.
GAN은 어떤 데이터 양식, 즉 이미지, 동영상, 음성, 텍스트 등에도 적용될 수 있다.
조건부 GAN으로 데이터셋 보강하기
GAN이 갖는 또 다른 큰 장점은 어떤 종류의 데이터로도 조건을 조정할 수 있다는 것이다.
| 조건부 GAN(conditional GAN, cGAN)은 입력값 y의 집합으로 조건이 지정된 이미지를 생성하는 조건부 분포 p(x | y)를 모델링하기 위해 훈련될 수 있다. 조건부 입력 y는 이미지, 범주형/연속형 레이블, 노이즈 벡터 또는 이들의 조합일 수 있다. |
조건부 GAN에서 판별기는 이미지 x(실제 또는 가짜)와 그에 대응하는 조건부 변수 y를 한 쌍의 입력으로 받는다.
조건부 GAN이 입력 이미지가 얼마나 ‘진짜’ 같은지를 측정하는 0과 1 사이의 값을 출력하지만, 그 과정은 GAN과 약간 다르다. ‘실제’ 이미지로 간주되려면 훈련 데이터셋에서 가져온 것처럼 보여야 할뿐더러 그와 쌍을 이루는 변수도 일치해야 한다.
실제 같지 않은 이미지와 더불어 조건에 부합하지 않는 데이터를 가짜 이미지로 취급 함으로써 특정 조건을 만족하도록 데이터를 생성할 수 있는 것이다.
예술적 애플리케이션으로 널리 알려져 있지만, 생성 모델은 장기적으로 복잡한 데이터셋을 이해하는 데 핵심이 될 수 있는 강력한 도구다.
오늘 날에는 훈련 데이터가 부족하더라도 더 견고한 인식 모델을 훈련하기 위해 사용되고 있다.
Leave a comment